Separation of single models
Appendix A
ASVSpoof dataset contains sapmples from 19 models of speech synthethis named A01-A19. Data from models A01-A06 is included in both train and validation splits, data from A07-A19 - in test split only.
In Section 4.3 of our article we show that individual heads are quite good at separating individual speech synthesize models, but due to lack of space we included results only for four of the models. Here we can present complete results for all 19 models. As in the article, for each of them we found a head that is the best at separating this model's speech from bonafide (as described in Section 4.3), plotted distributions of Hm, sym0, and found optimal in terms of Equal Error Rate (EER) threshold classifier. All those results are given in the table below.
Histograms for synthetic speech are given in red, for bonafide — in blue. Dashed line marks the threshold of optimal classifier. Please note that we enumerate layers and heads of HuBERT starting from 1. On the mobile phone slide left-to-right to see all the pictures.
A01, head 6 from layer 5 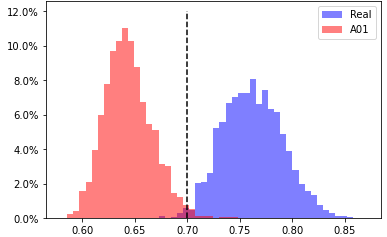
EER 0.9% at threshold 0.7 |
A02, head 5 from layer 9 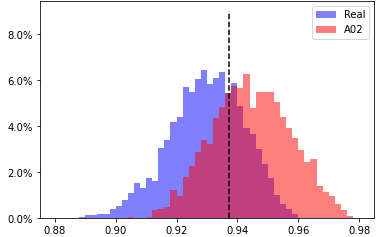
EER 29.805% at threshold 0.9372 |
A03, head 6 from layer 6 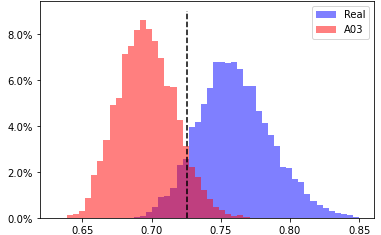
EER 11.00% at threshold 0.731 |
A04, head 6 from layer 5 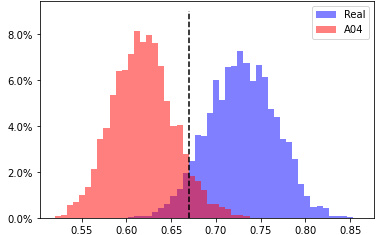
EER 6.577% at threshold 0.67 |
A05, head 5 from layer 5 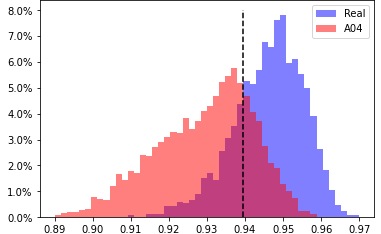
EER 22.5% at threshold 0.9396 |
A06, head 7 from layer 2 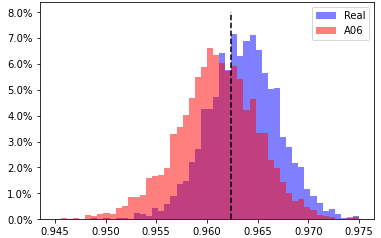
EER 34.404% at threshold 0.9624 |
A07, head 1 from layer 12 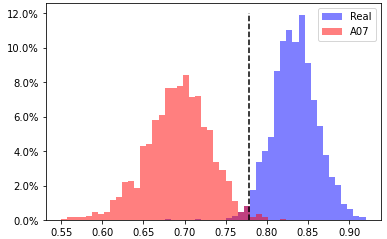
EER 1.00% at threshold 0.778 |
A08, head 3 from layer 6 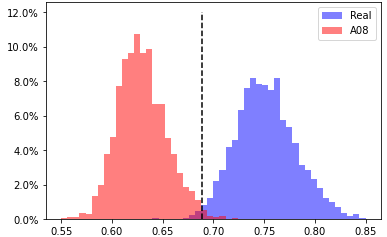
EER 1.0% at threshold 0.689 |
A09, head 3 from layer 6 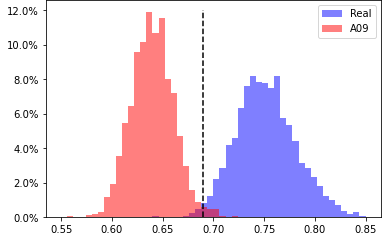
EER 1.2% at threshold 0.690 |
A10, head 1 from layer 7 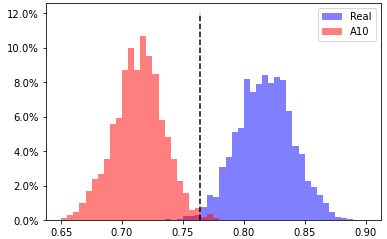
EER 0.7% at threshold 0.764 |
A11, head 1 from layer 12 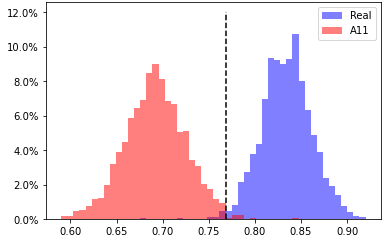
EER 0.7% at threshold 0.769 |
A12, head 5 from layer 7 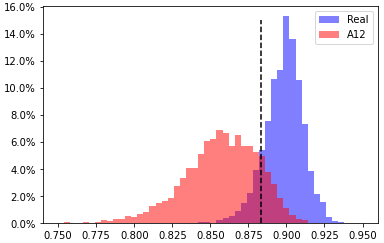
EER 12.57% at threshold 0.8831 |
A13, head 4 from layer 5 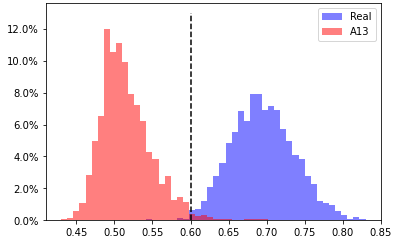
EER 1.0% at threshold 0.6 |
A14, head 1 from layer 12 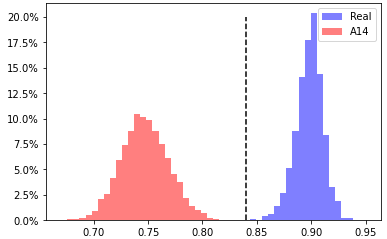
EER 0.03% at threshold 0.84 |
A15, head 1 from layer 12 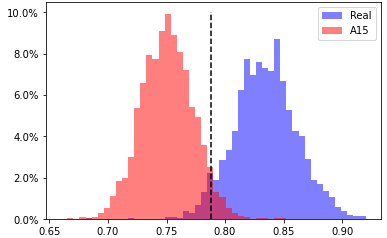
EER 4.3% at threshold 0.788 |
A16, head 12 from layer 7 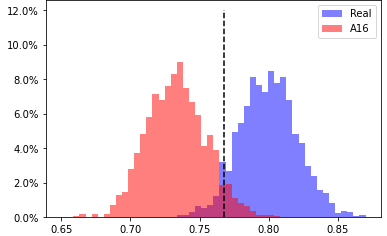
EER 5.87% at threshold 0.768 |
A17, head 5 from layer 5 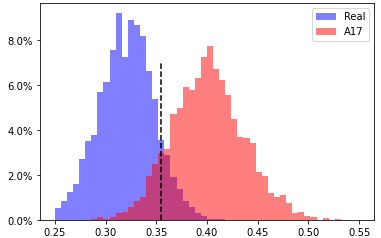
EER 9.7% at threshold 0.355 |
A18, head 7 from layer 2 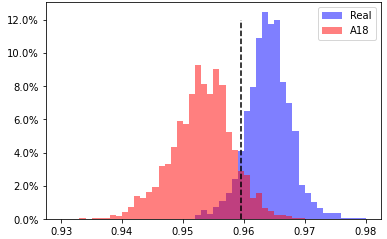
EER 8.6% at threshold 0.9595 |
A19, head 7 from layer 4 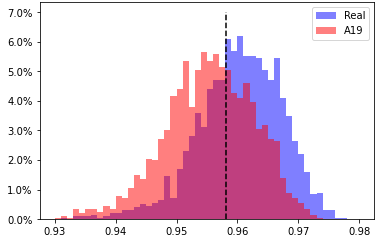
EER 35.6% at threshold 0.9581 |